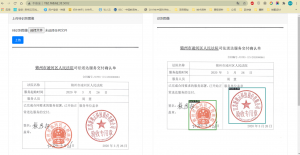
识别效果如上图
开源地址:https://gitee.com/zuiyuewentian/chapter_tagging
采用技术架构 Flask PaddlePaddle PaddleX
- 安装框架:Flask,PaddlePaddle,PaddleX
- python3.6以上版本
- 采用300多张印章的A4文件图片进行训练,采用slim工具进行压缩处理,模型大小为47M左右,在多核cpu下计算速度为0.1~0.2s之间,gpu为0.015s左右
- 请再服务器开放5002端口,访问http://localhost:5002 既可访问体验web版本
训练方法:
1.准备数据集
https://quqi.gblhgk.com/s/1832596/7IUtYKm839DrcMha
2.环境配置
安装python3.6 ,安装gpu运行环境cuda等,安装paddlepaddle 后再安装paddlex
3.选择目标检测算法
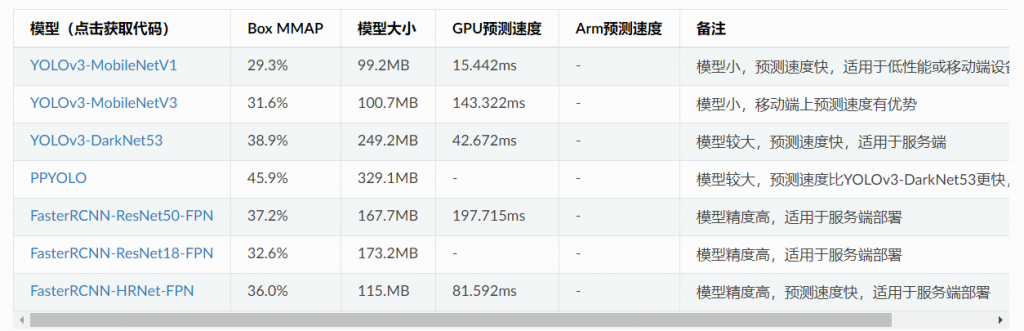
4.对图片集标注,使用百度Easydata在线标注(https://ai.baidu.com/easydata/app/dataset/list),或者精灵标注(标注后需要转成paddlex的格式)
5.图片分类训练集和和验证集以及测试集
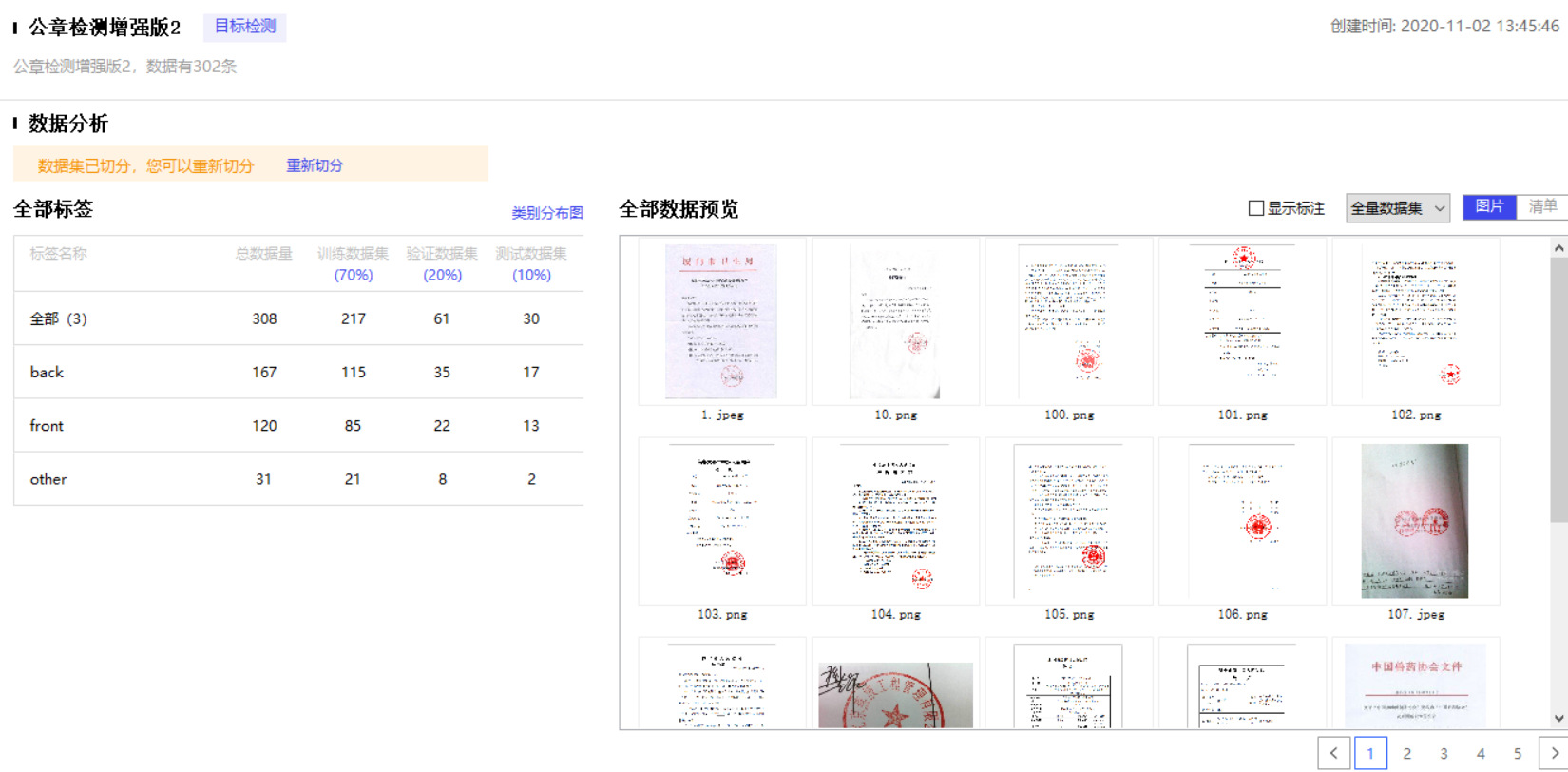
6.在gpu服务上执行训练(参考github文档使用,不同的算法不同使用方法)
# 环境变量配置,用于控制是否使用GPU
# 说明文档:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html#gpu
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from paddlex.cls import transforms
import paddlex as pdx
# 下载和解压蔬菜分类数据集
veg_dataset = 'https://bj.bcebos.com/paddlex/datasets/vegetables_cls.tar.gz'
pdx.utils.download_and_decompress(veg_dataset, path='./')
# 定义训练和验证时的transforms
# API说明https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/cls_transforms.html
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224), transforms.Normalize()
])
# 定义训练和验证所用的数据集
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-imagenet
train_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/val_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=eval_transforms)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.html
model = pdx.cls.ResNet50_vd_ssld(num_classes=len(train_dataset.labels))
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/models/classification.html#train
# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train(
num_epochs=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
learning_rate=0.025,
save_dir='output/resnet50_vd_ssld',
use_vdl=True)
7.训练好之后,下载模型测试,测试代码如下:
# 脚本运行依赖paddlex
# pip install paddlex
import paddlex as pdx
# 模型加载, 请将path_to_model替换为你的模型导出路径
# 可使用 mode = pdx.load_model('path_to_model') 加载
# 而使用Predictor方式加载模型,会对模型计算图进行优化,预测速度会更快
print("Loading model...")
model = pdx.deploy.Predictor('inference_model', use_gpu=False)
print("Model loaded.")
# 模型预测, 可以将图片替换为你需要替换的图片地址
# 使用Predictor时,刚开始速度会比较慢,参考此issue
# https://github.com/PaddlePaddle/PaddleX/issues/116
result = model.predict('test//unnamed.jpg')
# 可视化结果, 对于检测、实例分割务进行可视化
if model.model_type == "detector":
# threshold用于过滤低置信度目标框
# 可视化结果保存在当前目录
pdx.det.visualize('test//unnamed.jpg', result, threshold=0.5, save_dir='./')
8.部署模型导出
在服务端部署模型时需要将训练过程中保存的模型导出为inference格式模型,导出的inference格式模型包括__model__、__params__和model.yml三个文件,分别表示模型的网络结构、模型权重和模型的配置文件(包括数据预处理参数等)。
检查你的模型文件夹,如果里面是model.pdparams, model.pdmodel和model.yml3个文件时,那么就需要按照下面流程进行模型导出
在安装完PaddleX后,在命令行终端使用如下命令将模型导出。可直接下载小度熊分拣模型来测试本文档的流程xiaoduxiong_epoch_12.tar.gz。
paddlex --export_inference --model_dir=./xiaoduxiong_epoch_12 --save_dir=./inference_model
9.模型压缩,根据具体使用情景,提高识别率或者减小体积,选择对应的算法,此时模型应该非导出的模型,而是训练完的模型格式
参考文档:
https://paddlex.readthedocs.io/zh_CN/develop/slim/prune.html
https://github.com/PaddlePaddle/PaddleX
在线体验:
http://124.70.164.70:5003/
开源地址:

文章评论