def parseHtml(html): soup = BeautifulSoup(html, 'lxml') # print(soup.prettify)格式化输出 # items = soup.find_all('div', attrs={'class': 'news-list-b'}) # items = soup.select('Tag')#CSS选择器 # items = soup.select('.class')属性 # items = soup.select('#id')ID # items = so…

import os import fitz import requests #剪切pdf为图片 def CutPdf(pdfPath,savePath): try: doc = fitz.open(pdfPath) #pdf路径 for pg in range(doc.pageCount): if pg >= 1: break; page = doc[pg] rotate = int(0) # 每个尺寸的缩放系数为2,这将为我们生成分辨率提高四倍的图像。 zoom_x = 2.0 zoom_y = 2.0 t…
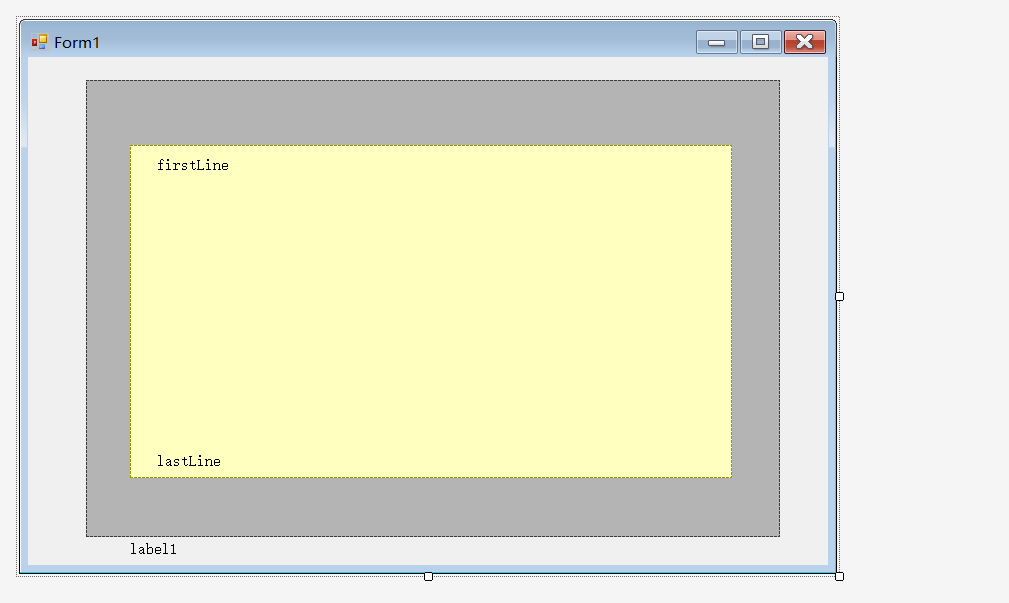
通过panel叠加实现 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; namespace LinPhoneTest { public partial class Form1 : Form { int…
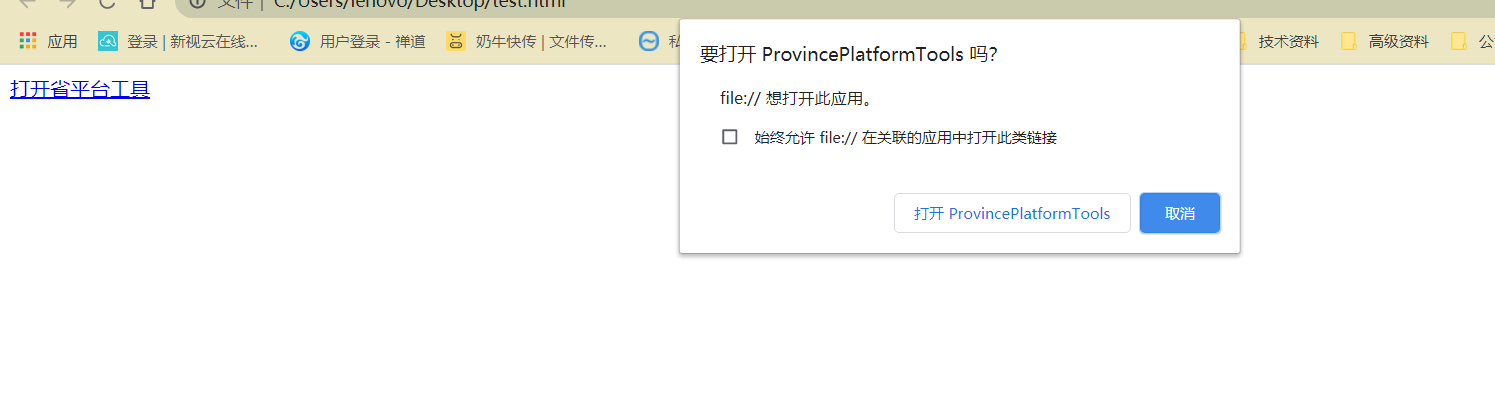
想要在网页调起本地的应用,需要在注册表里写入应用信息 详细见代码: using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using System.Text; namespace ProvincePlatformTools.Common { public static class RegisterTableHelper { /// /// 注册启动项到注册表 /// public st…

gitee封装:https://gitee.com/zuiyuewentian/CarouselForm.git 介绍 winform 封装一个幻灯片滚动动画 功能介绍 采用定时器+绘制自动以控件位置操作,并封装成工具,一句话调用即可实现动画效果。 动画展示,可以扩展幻灯片播放 使用方式,参考项目中: mainFormController.Init(5, 3, panel_Main.Width, panel_Main.Height); 参考实现代码: using System; using System.Colle…
处理判断图片是否空白页: /// <summary> /// 检查图片是否空白图片 /// </summary> /// <param name="img">Image</param> /// <returns>是否空白图片</returns> public static bool CheckTransparentImg(Bitmap bitMap) { try { bool blnIsTransparent = false; //图片总像素 …
常用easydata转换成目标识别库 import paddlex paddlex.tools.easydata2voc("test-data\\JPEGImages", "test-data\\Annotations", "test-data\\voc") 其他: 参数 其它数据集转换
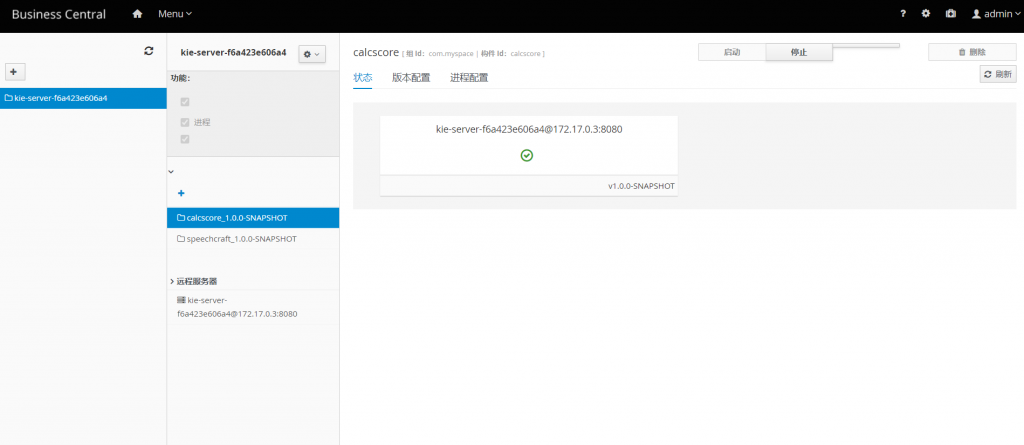
drools部署方案: 部署jboss/drools-workbench-showcase 部署jboss/kie-server-showcase 规则引擎手册地址:Drools5规则引擎开发教程.pdf
通常winform自带的三种定时器就足够用了,但是在某些场合,还存在着精度低,10ms以下不准的问题,现在推荐这款微秒级别的定时器 using System; namespace MicroLibrary { /// <summary> /// MicroStopwatch class /// </summary> public class MicroStopwatch : System.Diagnostics.Stopwatch { readonly double _microSecPer…