使用C# + Jumony开发网络爬虫
现在开发网络爬虫大部分都用python,发现用C#来写爬虫太少,我自己尝试用C#写了一个定向爬虫,在这里我向大家介绍它,目前已经把它开源到github上了,想要深入了解的朋友直戳下面的链接:
[https://github.com/zuiyuewentian/Reptile.git]
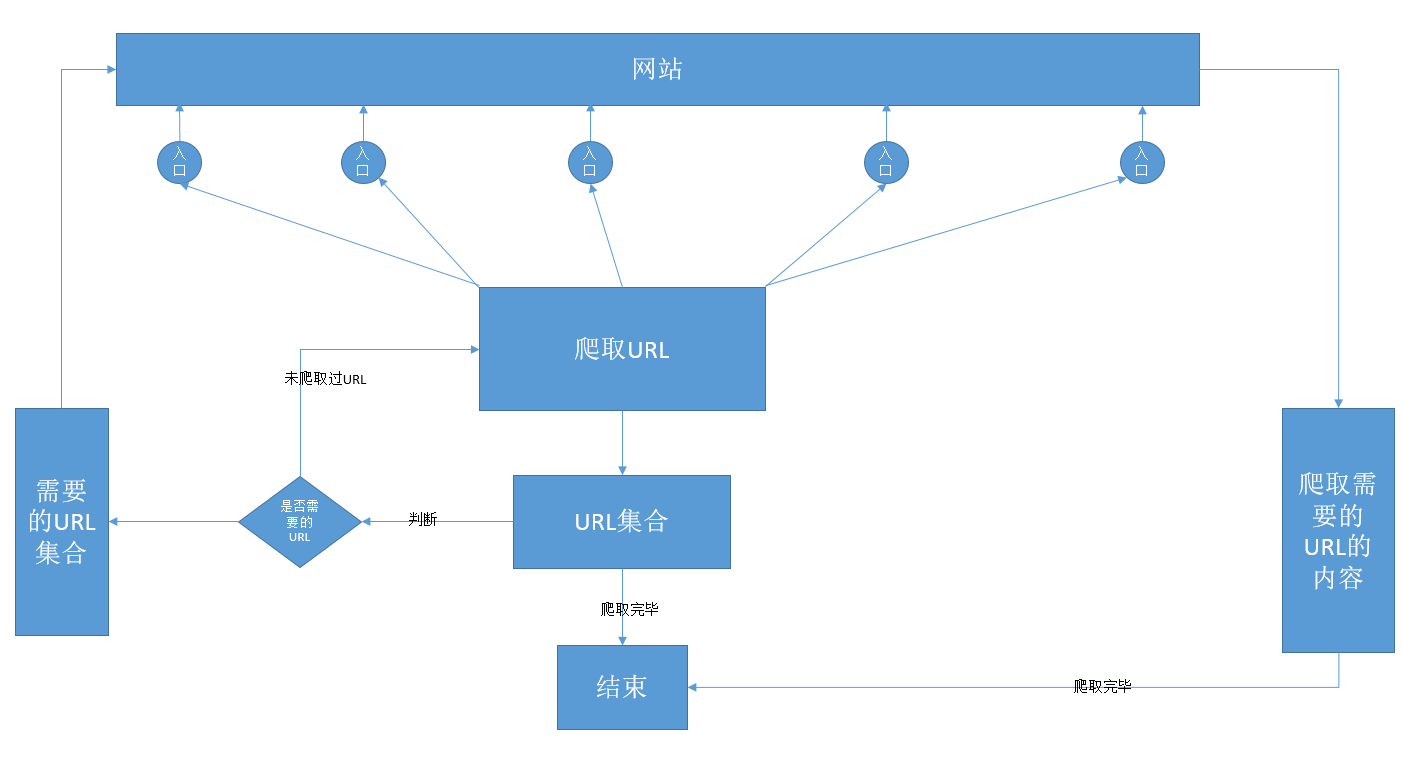
首先介绍下该爬虫的设计模型:
1.定义相关的网站入口,爬取内容页,爬取规则
2.使用多线程,从不同的网站入口开始爬取网站的URL链接
3.获取URL链接加入到待爬取链接的集合中
4.从待爬取的URL链接爬取有效URL加入到有效URL链接的集合中
5.同步读取有效URL链接中想要获取内容。
6.直到待爬取的URL链接爬取完毕,爬取URL链接的功能爬取完毕,直到有效URL链接的内容爬取完毕,同步读取URL获取内容结束,程序结束。
大致如图:
目前该爬虫的模型尚未加入元素:
1.加入代理IP功能,部分网站会对IP跟踪封杀爬虫。
2.未对相对链接URL做处理,目前爬虫只是爬取了a标签的href链接。
3.未对URL链接地址做压缩处理,节省了时间,但加大了内存的消耗。
4.未处理中断保存功能。
以上四点需要之后在此之上优化完善。
在写爬虫之前需要先了解下将会使用的jumony —— 一个HTML引擎,我在其中使用jumony作为解析HTML的工具,快速获取网页内容。
jumony是一个开源项目,相关资料可以去github上获取。使用的时候可以使用vs的NuGet管理搜索jumony安装到项目里即可使用,如图。
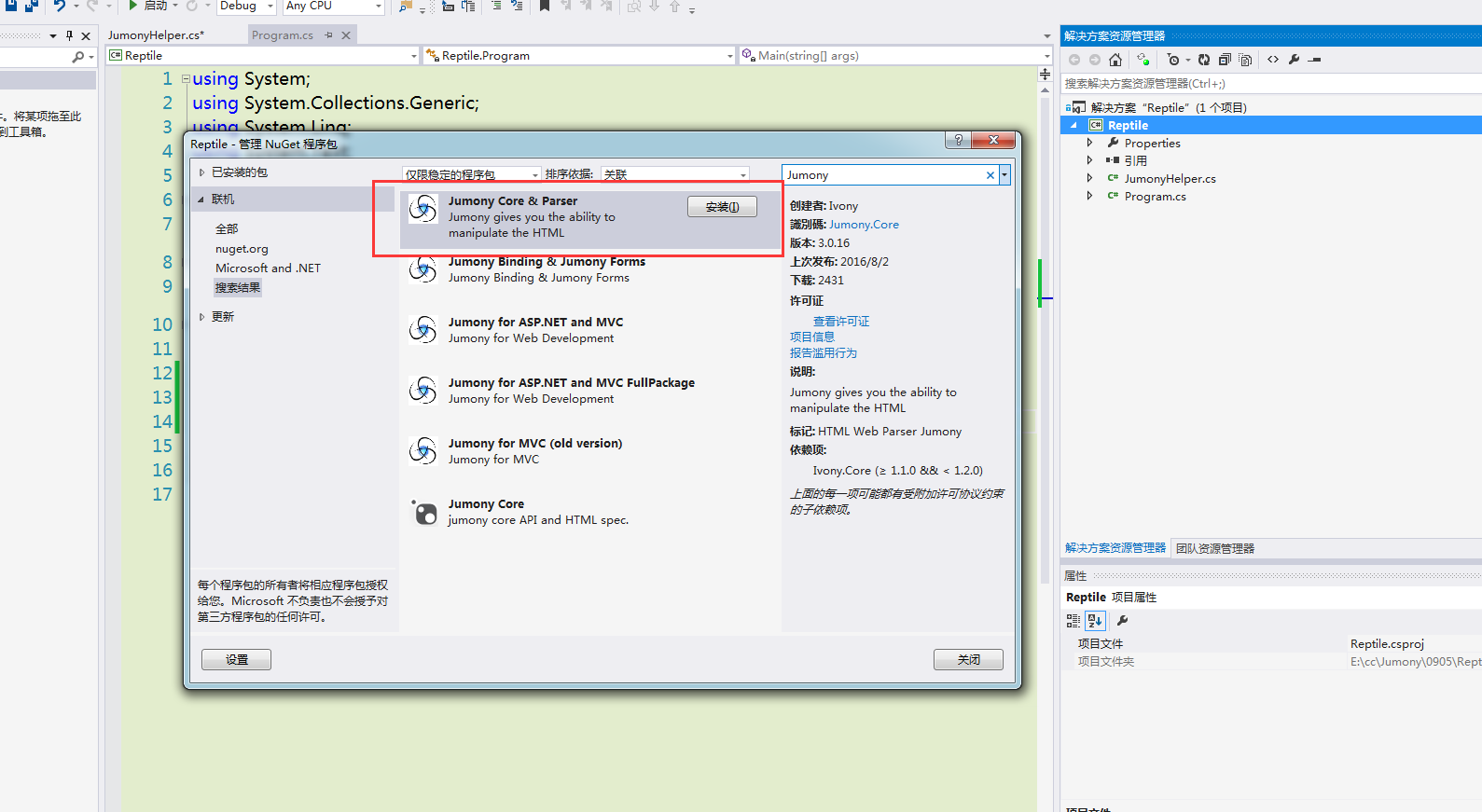
我在项目里简单的做了下封装来使用。
部分代码如下:
使用之前引用代码:
JumonyHelper内容:
using Ivony.Html;
private Ivony.Html.Parser.JumonyParser jumony;
public IHtmlDocument doc;
public JumonyHelper(string url)
{
jumony = new Ivony.Html.Parser.JumonyParser();
WebClient web = new WebClient();
web.Headers.Add("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36");
byte[] downData;
try
{
downData = web.DownloadData(url);
}
catch
{
return;
}
string html = Encoding.UTF8.GetString(downData);
doc = new Ivony.Html.Parser.JumonyParser().Parse(html);
// doc = new Ivony.Html.Parser.JumonyParser().LoadDocument(url);
}
/// <summary>
/// 获取同一个Class的内容
/// </summary>
/// <param name="cssKey">css样式关键字</param>
/// <returns></returns>
public List<string> GetClassTxt(string cssKey)
{
try
{
List<string> returnValue = new List<string>();
if (!doc.Exists(cssKey))
return null;
var values = doc.Find(cssKey);
if (values == null)
return null;
foreach (var item in values)
{
returnValue.Add(item.InnerText());
}
return returnValue;
}
catch (Exception ex)
{
return null;
}
}
/// <summary>
/// 获取元素Id的内容
/// </summary>
/// <param name="cssKeyId">css样式id</param>
/// <returns></returns>
public string GetElementByIdTxt(string cssKeyId)
{
try
{
if (!doc.Exists(cssKeyId))
return null;
var values = doc.GetElementById(cssKeyId);
if (values == null)
return null;
return values.InnerText();
}
catch (Exception ex)
{
return null;
}
}
这里,我放弃了使用jumony的加载url的方法LoadDocument,使用WebClient的DownloadData方法。
原因是jumony的方法里似乎没有找到处理网页编码的方法,这让我略显无奈,而且jumony相关学习资料也不多,乱码问题没办法解决。
这里实例化后主要提供出doc的节点自己调用,也可以调用下面获取id或者获取class的方法。
相关jumony的css选择器功能可以去jumony社区查询,在本项目中使用方法,也是使用了基本的css选择器方法,可以作为相关参考。
该项目以爬取伯乐在线(http://www.jobbole.com/)用户信息为实例,并对爬取的用户做数据分析。
1.配置相关参数
BASEURL = "jobbole.com" 所属网站,,URL链接不能超出该网站的范畴
NEEDURL = "jobbole.com/members"最终需要匹配的URL规则关键字
ThreadCount = 1;开启线程数量
BASEURLDEPTH = 4; 爬虫的深度要求不能大于BASEURLDEPTH
NEEDURLDEPTH = 3;所需要的URL深度要求=NEEDURLDEPTH
2.爬取需要的页面URL链接功能部分代码:
/// <summary>
/// 开始爬取
/// </summary>
public void ReptileStart()
{
ThreadList = new Thread[ThreadCount];
for (int thread = 0; thread < ThreadCount; thread++)
{
ThreadList[thread] = new Thread(new ParameterizedThreadStart(Reptile));
ThreadList[thread].Name = "myThread" + thread;
ThreadList[thread].IsBackground = true;
ThreadList[thread].Start(PageStartURL[thread]);
}
}
public void Reptile(object url)
{
//初始网址抓取
string repUrl = url.ToString();
ReptileURL(repUrl);
lock (ReptileObj)
{
ReptileUrl.Add(repUrl);
}
lock (VisitedObj)
{
VisitedUrl.Add(repUrl);
}
//循环抓取
int startIndex = 0;
while (true)
{
int reptileUrlCount = ReptileUrl.Count();
if (reptileUrlCount <= 0)
break;
if (reptileUrlCount <= VisitedUrl.Count())
{
IsEndReptile = true;
break;
}
for (int i = startIndex; i < reptileUrlCount; i++)
{
string rurl = ReptileUrl[i];
// 去除重复爬网页
if (VisitedUrl.Contains(rurl))
continue;
ReptileURL(rurl);
lock (VisitedObj)
{
VisitedUrl.Add(rurl);
}
}
startIndex = reptileUrlCount;
}
}
/// <summary>
/// NeedUrl ID
/// </summary>
int MemberIndex = 1;
/// <summary>
/// 爬取网页中a标签的链接地址
/// </summary>
/// <param name="url"></param>
public void ReptileURL(string url)
{
if (!IsBaseUrl(url))
return;
JumonyHelper jumonyHelper = new JumonyHelper(url);
if (jumonyHelper.doc == null)
return;
var urlList = jumonyHelper.doc.Find("a[href]");
if (urlList == null)
return;
foreach (var item in urlList)
{
string itemUrl = item.Attribute("href").Value();
if (!ReptileUrl.Contains(itemUrl))
{
lock (ReptileObj)
{
ReptileUrl.Add(itemUrl);
}
if (IsNeedUrl(itemUrl))
{
itemUrl = itemUrl.TrimEnd('/');
if (!NeedUrlList.Contains(itemUrl))
{
lock (NeedObj)
{
NeedUrlList.Add(itemUrl);
insertURLXML(MemberIndex, itemUrl);
MemberIndex++;
}
}
}
}
}
}
3.爬取内容页部分代码
int UserIndex = 1;
public void LoadUser(string userUrl)
{
MemberEntity member = new MemberEntity();
member.url = userUrl;
try
{
JumonyHelper jumonyHelper = new JumonyHelper(userUrl);
var nameValue = jumonyHelper.doc.FindFirst(".profile-title");
string name = nameValue.InnerText();
member.name = name;
var profiles = jumonyHelper.doc.Find(".profile-points > li");
foreach (var item in profiles)
{
string value = item.InnerText();
if (value.Contains("\r\n"))
{
value = value.Replace("\r\n", "|");
string[] pros = value.Split('|');
if (pros[1] == "声望")
{
member.reputation = pros[0];
}
else if (pros[1] == "勋章")
{
member.medal = pros[0];
}
else if (pros[1] == "积分")
{
member.point = pros[0];
}
}
}
var profile = jumonyHelper.doc.FindFirst(".profile-bio");
member.profile = profile.InnerText();
var follows = jumonyHelper.doc.Find(".profile-follow");
foreach (var item in follows)
{
string value = item.InnerText();
if (!String.IsNullOrEmpty(value))
{
if (value.Contains("关注"))
{
string following = value.Split('(')[1].Split(')')[0];
member.following = following;
}
else if (value.Contains("粉丝"))
{
string follower = value.Split('(')[1].Split(')')[0];
member.follower = follower;
}
}
}
var infos = jumonyHelper.doc.Find(".member-info > span");
foreach (var item in infos)
{
string value = item.InnerText();
if (!String.IsNullOrEmpty(value))
{
if (value.Contains("注册"))
{
string date = value.Split(':')[1];
member.Date = date;
}
else if (value.Contains("城市"))
{
string city = value.Split(':')[1];
member.city = city;
}
}
}
var image = jumonyHelper.doc.FindFirst(".profile-img > a > img");
string imageUrl = image.Attribute("src").Value();
member.image = imageUrl;
if (jumonyHelper.doc.Exists("i[title]"))
{
var sexHtml = jumonyHelper.doc.FindFirst("i[title]");
string sex = sexHtml.Attribute("title").Value();
member.sex = sex;
}
else
{
member.sex = "";
}
member.Id = UserIndex;
lock (ReptileObj)
{
memberHelper.AddMember(member);
insertXML(member);
UserIndex++;
}
}
catch (Exception ex)
{
WriteTxt.WriteNewTxt("ERRORLOG", "++++错误数据+++" + ex.Message);
}
}
了解详细内容请查看github项目。
爬虫项目到现在为止大致介绍完毕,请大家需要注意一下几点:
1.爬虫对目标网站会造成流量攻击,甚至会导致目标网站奔溃,请大家合理利用爬虫,可以设置爬取时间再深夜时段或者,爬取一段暂停一段时间。
2.请选择合适的入口,以连接本站页面多为好。
3.开启多线程爬取时应该以使用电脑的效率最高为目的,而不应该随意开启太多线程。
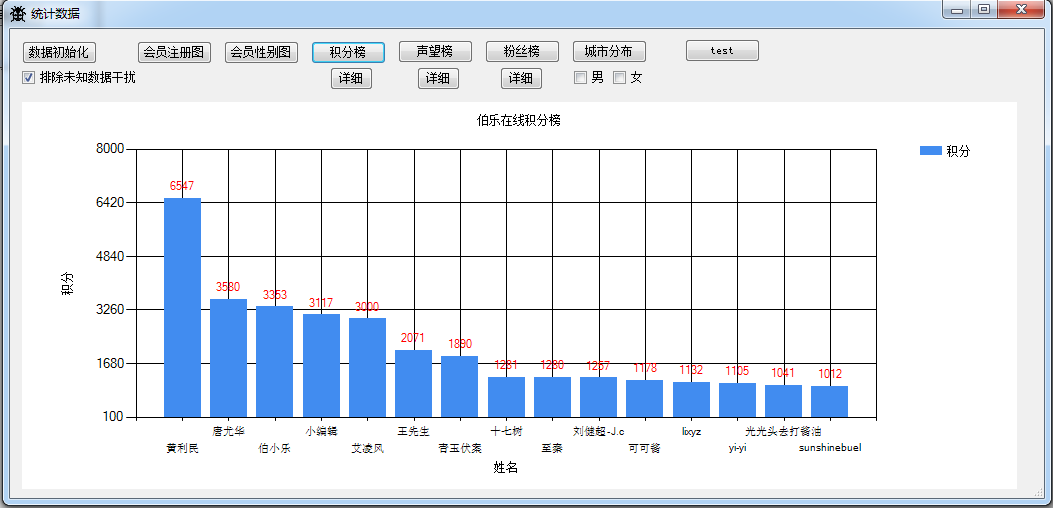
这边统计对伯乐在线用户爬取共计6000多人,活跃用户大约1000多人,以下是用户的具体情况图
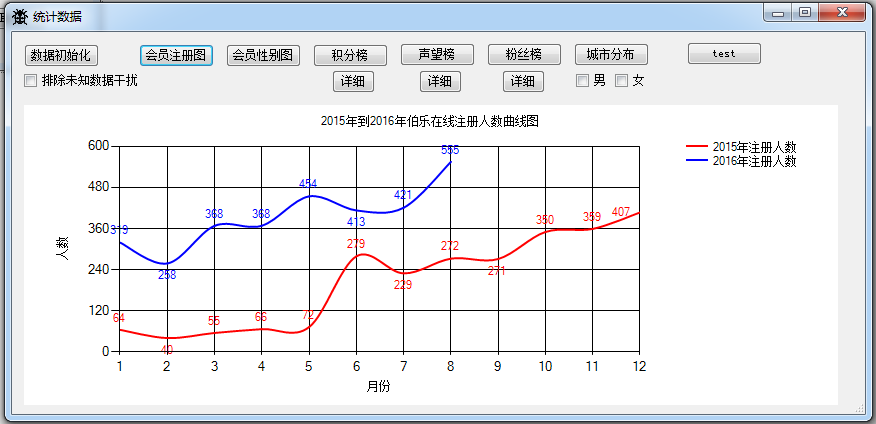
1.2015年和2016年伯乐在线注册情况曲线图
此图明显可以看出2016年注册人数比2015年人数要多很多,影响力日益变大,可以预计2~3年左右伯乐将会成为一个颇有影响力程序员社区。
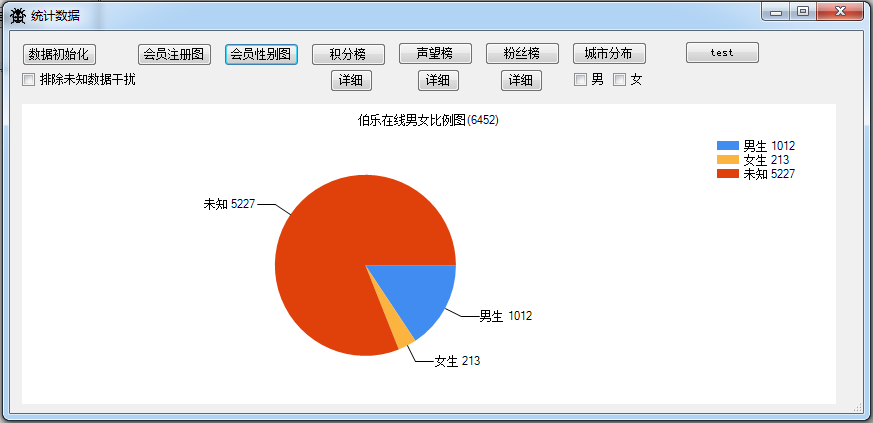
2.伯乐在线男女比例图
伯乐的注册没有设置性别必填,导致统计男女数量里有大量的未知数据,基本可以判断,非活跃用户肯定大部分处于未知用户中
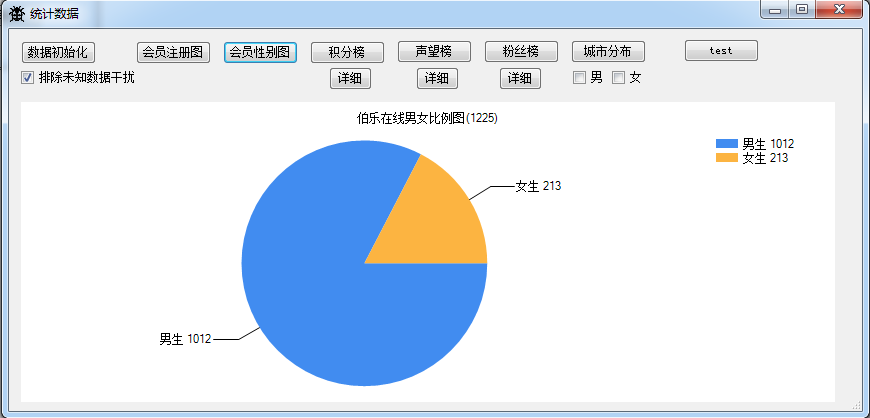
3.伯乐在线男女比例图
排除未知数据干扰,大约可以判断男生大约占用户总数的80%以上
4.伯乐在线积分榜
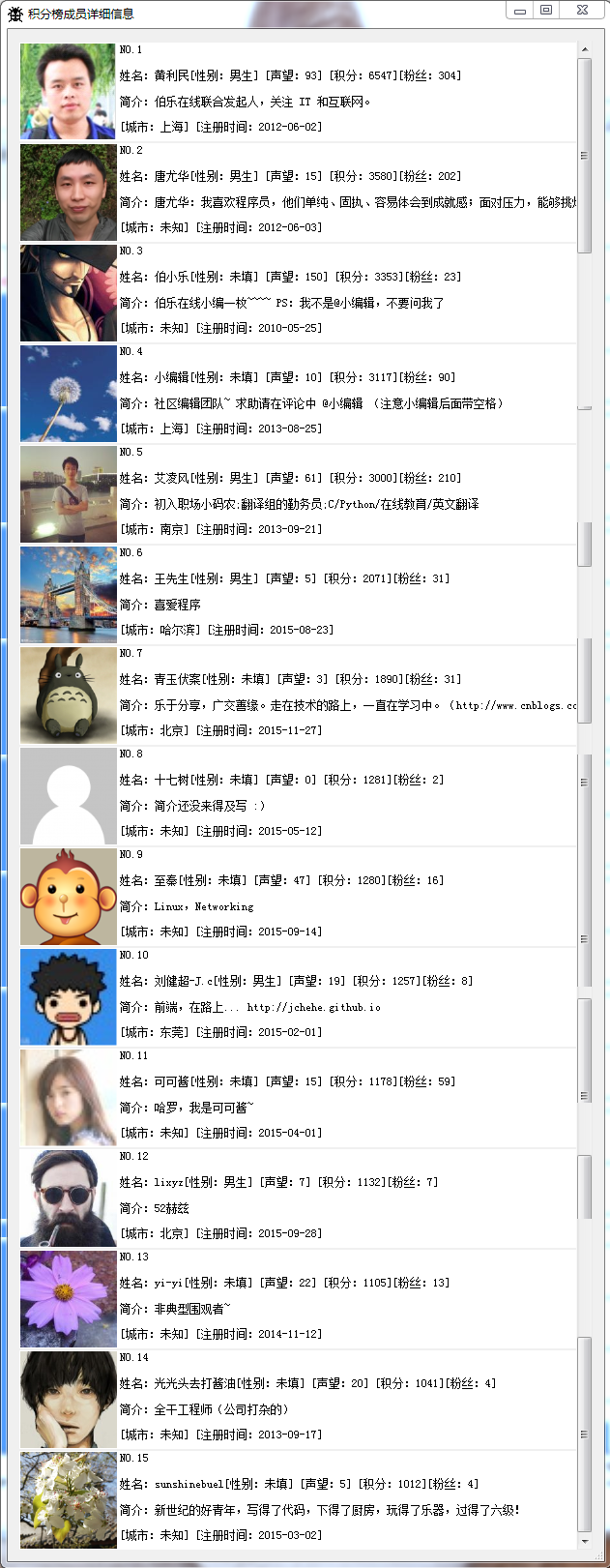
看看这些人的具体是那些?
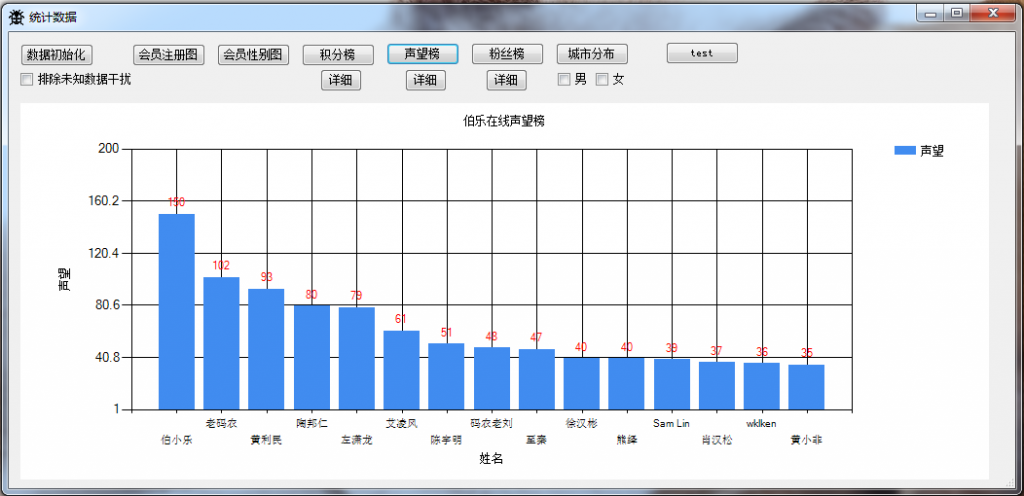
5.伯乐在线声望榜
6.伯乐在线粉丝榜
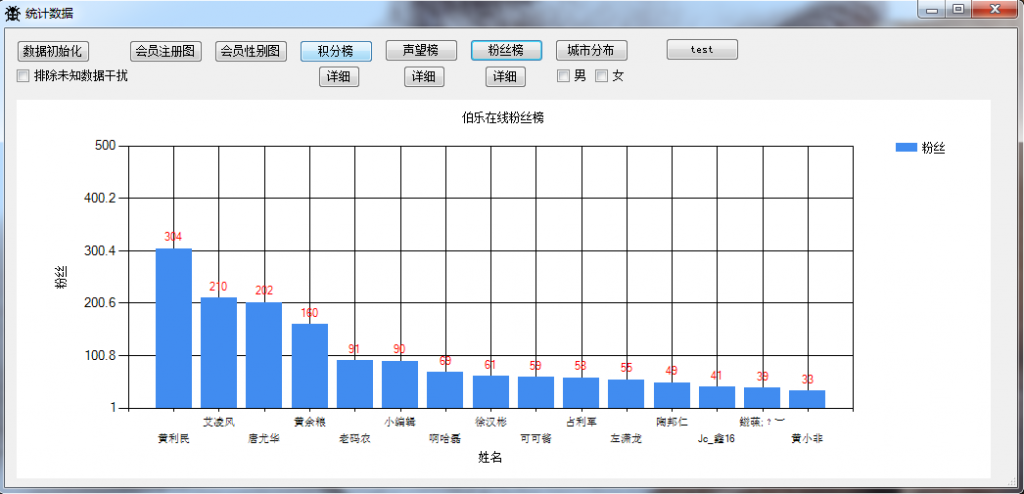
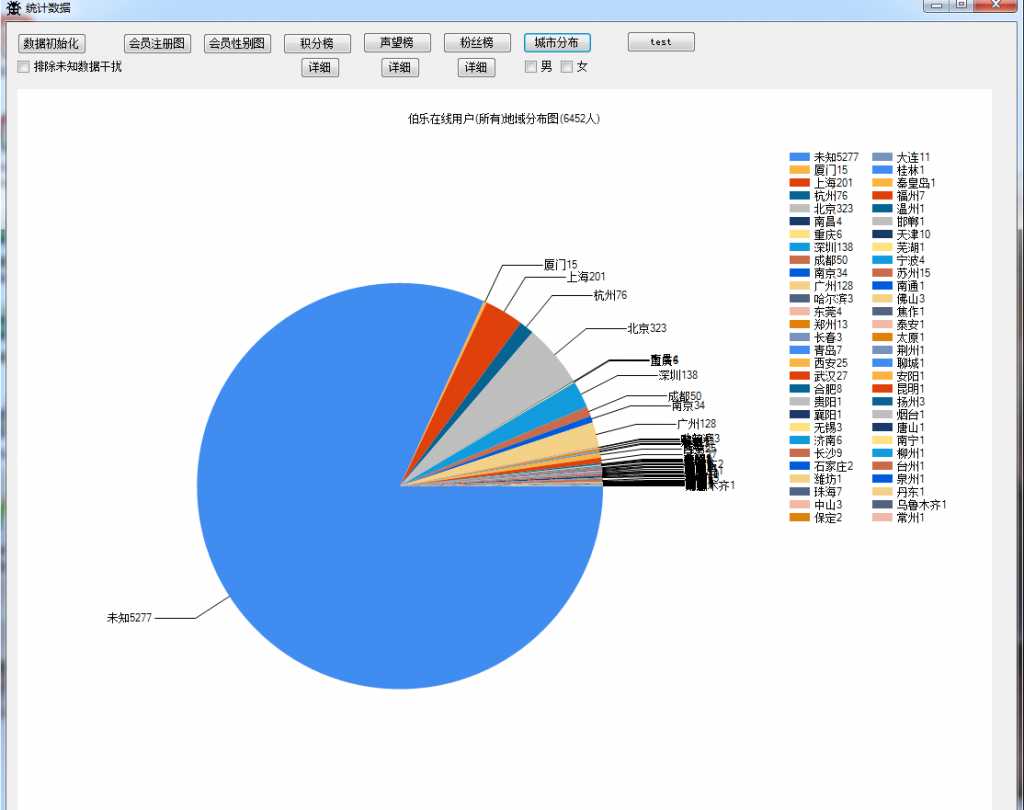
7.伯乐在线用户地域分布图
因为伯乐地域字段可以自定义,所以这里地域过滤了无关数据,取中国地市为标准,其他一律归入未知。
在这里我们可以看出伯乐的用户大部分分布在北京,上海,广州,深圳

文章评论